
ClickHouse представляет из себя колоночную систему управления базами данных наиболее подходящую под приложения, работающие с онлайн-запросами на структурированных больших данных. Другими словами ClickHouse – это СУБД для работы с Big Data. Данная система является Open Source продуктом компании Yandex. В ClickHouse используется диалект SQL, поддерживающий декларативный язык запросов. Данный диалект во многих аспектах совпадает со стандартами SQL. В данном мануале рассмотрим, как можно установить и использовать ClickHouse на сервере, работающем на Ubuntu 20.04.
Подготовка сервера
Если вы планируете использовать для установки ClickHouse только что созданный виртуальный сервер, то вам необходимо произвести на нём работы подготовительного характера. А именно, создать пользователя, имеющего привилегии администратора, чтобы не подключаться к серверу непосредственно при помощи учётной записи root. А также, произвести предварительную настройку и запуск брандмауэра. Эти меры позволят вам значительно повысить уровень безопасности сервера. Как это сделать, описано в соответствующей статье нашего справочника.
И перед тем, как начать установку дополнительного программного обеспечения, необходимо обновить индексы пакетов в системе, а также, провести обновление самих пакетов до актуальных на текущий момент версий:
$ sudo apt update$ sudo apt upgradeТеперь всё готово к установке СУБД.
Установка ClickHouse
Yandex осуществляет поддержку репозитория apt, содержащего актуальную версию ClickHouse. Для того, чтобы добавить данные по этому репозиторию в нашу систему, необходимо сначала установить соответствующие зависимости:
$ sudo apt install apt-transport-https ca-certificates dirmngrЗатем, нужно добавить GPG-ключ репозитория:
$ sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 8919F6BD2B48D754В случае успешной загрузки пакетов, вывод операции должен выглядеть примерно следующим образом:

Далее, добавьте репозиторий в систему:
$ echo "deb https://packages.clickhouse.com/deb stable main" | sudo tee \
/etc/apt/sources.list.d/clickhouse.listИ ещё раз запустите обновление индекса пакетов:
$ sudo apt updateЗаключительный шаг установки – непосредственно инсталляция серверной и клиентской части ClickHouse:
$ sudo apt install clickhouse-server clickhouse-clientВ ходе установки система запросит установить пароль, который будет использоваться в дальнейшем для доступа к интерфейсу СУБД:
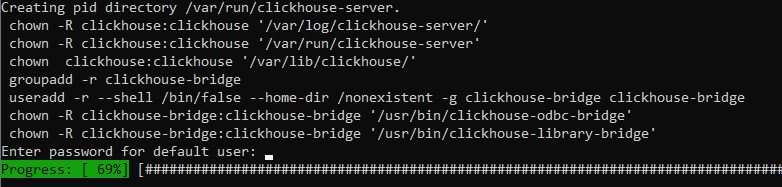
Запуск ClickHouse
В результате мы получили службу clickhouse-server, которую, как и всякую другую, нужно запустить после её установки:
$ sudo service clickhouse-server startТеперь проверьте состояние запущенного сервиса, чтобы убедиться в отсутствии ошибок:
$ sudo service clickhouse-server statusСтатус службы должен выглядеть приблизительно так:
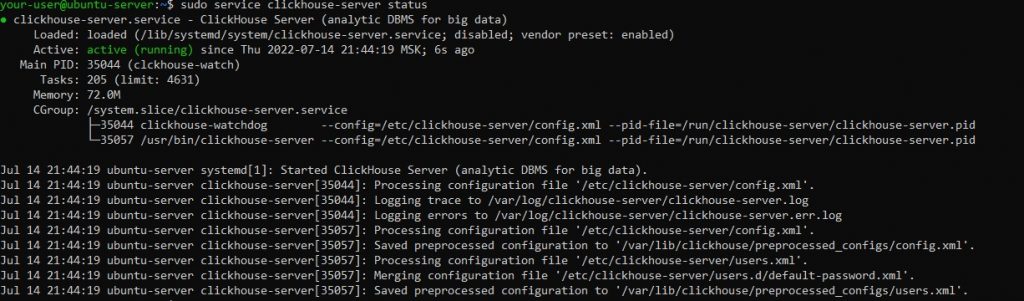
Наконец, можно подключиться непосредственно к СУБД. Для этого используется команда clickhouse-client:
$ clickhouse-client --password --multilineВ нашем примере мы подключаемся с иcпользованием параметров:
--password– требует ввода пароля при входе;--multiline– разрешает отправлять многострочные запросы.

Создание баз данных и таблиц
Интерфейсом ClickHouse является интерактивная командная строка. Управление данными происходит путём ввода в командную строку инструкций, которые должны подчиняться определенному синтаксису. Приглашение ко вводу SQL-команды выглядит как :)
Далее, мы попробуем произвести некоторые действия с данными при помощи ClickHouse.
Подключившись к СУБД, создайте базу данных mydb:
:) CREATE DATABASE mydb;СУБД сообщит об успешном создании базы данных следующим образом:
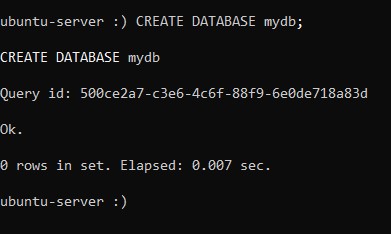
Для того, чтобы использовать только что созданную базу, переключитесь на неё при помощи оператора USE:
:) USE mydb;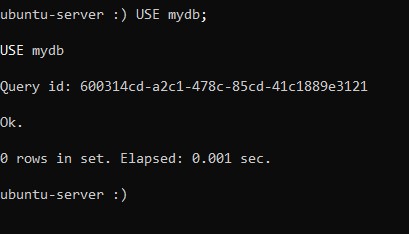
Создание таблицы
Структура таблиц ClickHouse идентична структуре таблиц в других подобных реляционных системах. При создании таблиц в ClickHouse применяется следующий синтаксис:
CREATE TABLE table_name
(
column_name_1 column_type [options],
column_name_2 column_type [options]
...
) ENGINE = engineВ данном случае, table_name – название таблицы, column_name_1 и column_name_2 – названия столбцов. Каждый столбец обязан иметь определённый тип. Вот, список наиболее часто используемых типов:
UInt64– целые числа в диапазоне от 0 до 18446744073709551615;Float64– числа с плавающей точкой;String– символьные переменные;Date– дата в формате YYYY-MM-DD;DateTime– дата и время в формате YYYY-MM-DD HH:MM:SS.
Параметр ENGINE отвечает за движок, который будет использоваться в таблице. При помощи этого параметра определяются физическая структура данных, характер поддержки запросов, режимы доступа к данным, поддержка индексов, возможность многопоточного выполнения запросов, параметры репликации. Наиболее универсальным семейством движком является MergeTree.
Исходя из этого давайте попробуем создать новую таблицу в базе mydb. В качестве примера мы будем использовать для нашей таблицы следующую структуру:
id– уникальный идентификатор строки;val– десятичное число;wrd– символьная строка;dt– дата и время.
Для создания таблицы mytable в командной строке наберите следующие строки:
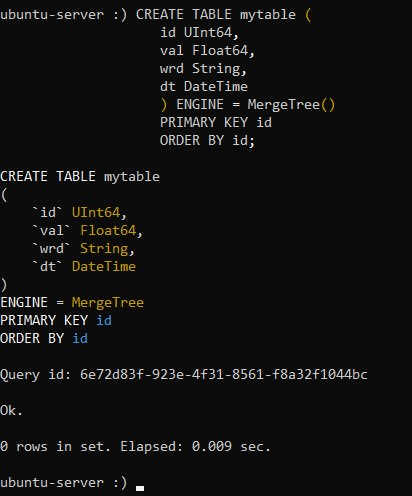
:) CREATE TABLE mytable (
id UInt64,
val Float64,
wrd String,
dt DateTime
) ENGINE = MergeTree()
PRIMARY KEY id
ORDER BY id;После перечисления названий и типов столбцов необходимо указать тип движка для новой таблицы. Благодаря наиболее оптимизированной поддержке больших вводов в реальном времени, общей надёжности и поддержке запросов, рекомендуется использовать тип движка MergeTree. Его мы и указываем в параметре ENGINE. Плюс к этому мы используем опцию PRIMARY KEY. Она определяет столбец id в качестве первичного ключа. В свою очередь, опция ORDER BY указывает на то, что данные в новой таблице будут отсортированы по столбцу id.
При выполнении команды система сообщит о создании новой таблицы:
Вставка, обновление и удаление данных
После того, как вы создали новую таблицу в тестовой базе данных, можно посмотреть как происходит вставка, обновление и удаление данных в ней.
Команда для вставки строки в таблицу имеет следующий синтаксис:
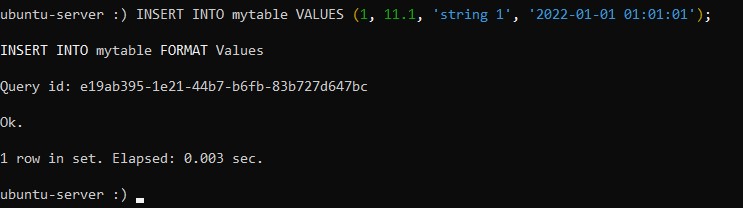
INSERT INTO table_name VALUES (column_value_1, column_value_2, column_value_3 ....);Применяя данный образец написания команды, вставьте несколько различных строк в таблицу mytable:
:) INSERT INTO mytable VALUES (1, 11.1, 'string 1', '2022-01-01 01:01:01');
:) INSERT INTO mytable VALUES (2, 22.2, 'string 2', '2022-02-02 02:02:02');
:) INSERT INTO mytable VALUES (3, 33.3, 'string 3', '2022-03-03 03:03:03');При успешном добавлении каждой из строк система выводит следующее сообщение:
Также, в существующую таблицу можно добавить столбец. Такая команда имеет следующий формат:
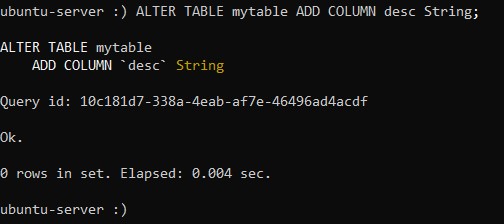
ALTER TABLE table_name ADD COLUMN column_name column_type ;Используя это правило, давайте добавим в нашу таблицу столбец, предназначенный для содержания неких текстовых данных, например, комментарий:
:) ALTER TABLE mytable ADD COLUMN desc String;Вывод успешного добавления будет следующим:
После того, как вы наполнили таблицу некоторым количеством данных, давайте посмотрим, как эти данные можно изменить.
Синтаксис команды, предназначенная для обновления строк таблицы, выглядит следующим образом:
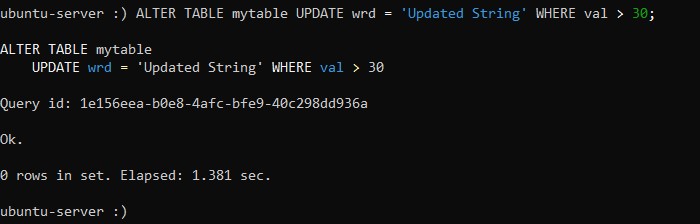
ALTER TABLE table_name UPDATE column_name_1 = column_value_1, column_name_2 = column_value_2, column_name_3 = column_value_3 ... WHERE filter-conditions;Исходя из этого, измените содержимое столбца wrd в тех строках, где значение столбца val больше, чем 30. Запись команды, предназначенной для выполнения такого задания, выглядит так:
:) ALTER TABLE mytable UPDATE wrd = 'Updated String' WHERE val > 30;При успешном применении изменений вывод будет следующим:
В свою очередь, команда, предназначенная для удаления строк из таблицы, имеет следующий порядок записи:
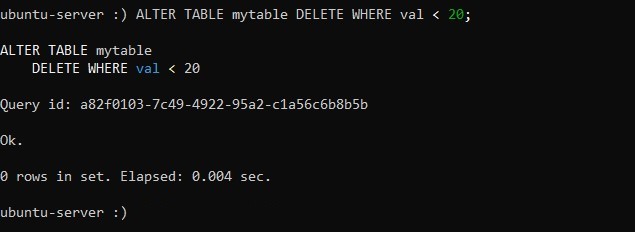
ALTER TABLE table_name DELETE WHERE filter_conditions;Таким образом, команда для удаления из таблицы строк, у которых значение столбца val меньше, чем 20, примет такой вид:
:) ALTER TABLE mytable DELETE WHERE val < 20;Соответственно, так выглядит вывод команды, выполненной без ошибок:
Кроме удаления строки из таблицы, в ClickHouse существует возможность удаления столбца. Структура такой команды следующая:
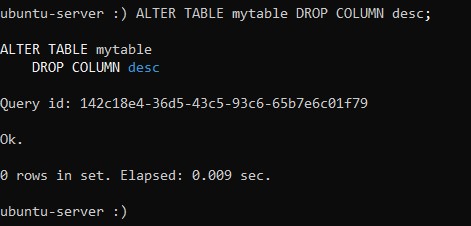
ALTER TABLE table_name DROP COLUMN column_name;Удалите из своей таблицы столбец desc, тот самый, который мы добавляли отдельной командой:
:) ALTER TABLE mytable DROP COLUMN desc;Если удаление произведено, система сообщит следующее:
Теперь, когда вы поэкспериментировали с изменением данных тестовой таблицы, давайте посмотрим, как создаются запросы к этим самым данным.
Запрос данных
ClickHouse обрабатывает запросы, созданные на языке, основой которого является SQL. В данном разделе давайте посмотрим, как формируются выборки данных из ранее созданной таблицы. Делать это мы будем именно при помощи запросов к ней.
Запросы представляют из себя выражения, с помощью которых можно получить определённые выборки данных, отфильтрованные по неким условиям. Основным оператором для этого является оператор SELECT. Его синтаксис выглядит следующим образом:
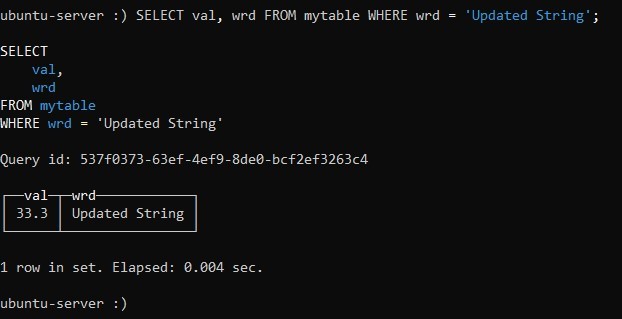
SELECT function_1(column_name_1), function_2(column_name_2) FROM table_name WHERE filter_conditions row_options;Исходя из этого, запустите команду для запроса, который сможет показать нам данные из столбцов val и wrd только для тех строк, столбец которых wrd содержит значение Updated String:
:) SELECT val, wrd FROM mytable WHERE wrd = 'Updated String';В нашем случае выборка получилась следующая:
Кроме того, в изучаемой нами СУБД широкое применение получили так называемые агрегационные запросы. Это – такие запросы, которые оперируют целым набором данных и возвращают единичное выходное значение. Одним из операторов, которые умеют обрабатывать такие запросы, является оператор COUNT. Этот оператор возвращает количество строк, соответствующих указанным определённым условиям. Ещё один подобного типа оператор – это SUM. Он, в свою очередь, возвращает сумму значений указанных столбцов А вот, оператор AVG возвращает среднее значение столбцов, соответствующих определённому фильтру.
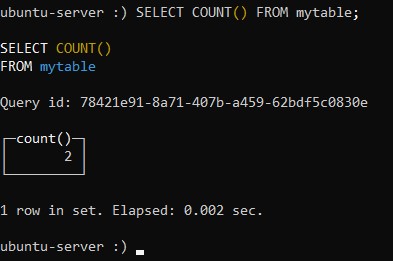
Посмотрим, как это работает. Давайте запросим из нашей таблицы количество записей, содержащейся в ней. Команда, способная выдать такую выборку, может быть записана следующим образом:
:) SELECT COUNT() FROM mytable;И вот, что она нам показала:
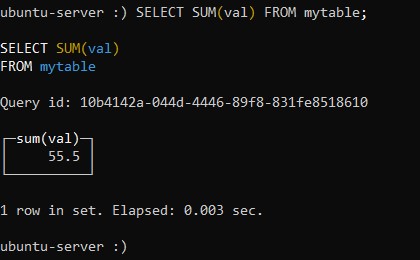
А вот, как будет выглядеть запись команды для запроса суммы всех записей по столбцу val:
:) SELECT SUM(val) FROM mytable;Ответ на наш запрос будет следующим:
Удаление таблиц и баз данных
После того, как мы завершили эксперименты с данными при помощи СУБД ClickHouse, давайте посмотрим, каким образом произвести удаление нашей таблицы, а затем и базы данных.
В отношении таблицы оператор удаления имеет следующий синтаксис:
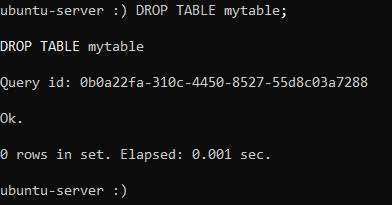
DROP TABLE table_name;Основываясь на этом, можно удалить нашу таблицу:
:) DROP TABLE mytable;Сообщение об удалении таблицы будет таким:
Команда удаления базы данных выглядит почти так же:
:) DROP DATABASE mydb;Соответственно, выведенное системой сообщение так же очень похоже:
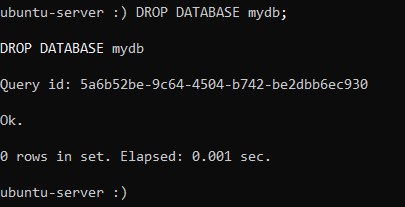
Следы наших экспериментов, а именно, таблица и, содержавшая её, база данных, удалены.
Заключение
Таким образом, на вашем виртуальном сервере теперь функционирует СУБД ClickHouse. Также, мы посмотрели, как производятся самые простые действия с базами данных и таблицами. Мы попробовали создать базу данных и таблицу в ней, мы посмотрели, как добавлять в созданную таблицу данные, как их изменять и удалять. Данное руководство – это всего лишь первоначальное знакомство с ClickHouse. Более полную информацию вы найдёте на официальной странице ClickHouse.
