
В данном мануале мы рассмотрим, как установить и приступить к использованию Apache Kafka на сервере под управлением Ubuntu Server 20.04.
Apache Kafka – популярный механизм обмена сообщениями, который позволяет осуществлять передачу сообщений с более высокой пропускной способностью по сравнению с другими брокерами сообщений (RabbitMQ, ActiveMQ). Система разработана компанией LinkedIn и используется для передачи данных в хранилище, ведения логов событий, потоковой аналитики и т.п. Apache Kafka обеспечивает публикацию сообщений не принимая во внимание количество потребителей и то, как данные потребители обрабатывают полученные сообщения.
Предварительные требования
Установку и настройку Apache Kafka в рамках настоящей инструкции мы будем выполнять на сервере, работающем под управлением Ubuntu Server 20.04. Ваш виртуальный сервер должен иметь минимум 4 ГБ оперативной памяти для того, чтобы избежать сбоев в работе сервиса Kafka.
Для обеспечения более высокого уровня безопасности, крайне рекомендуется выполнить работы по первоначальной настройке виртуального сервера, согласно соответствующей статье нашего справочника. А именно, необходимо создать и наделить привилегиями sudo специального пользователя, которого вы будете использовать вместо учётной записи root. Также, нужно произвести запуск и первоначальную настройку брандмауэра, а заодно и закрыть доступ к серверу по SSH для пользователя root.
Подготовка к установке
Как всегда, перед инсталляцией каких-либо приложений, запустите обновление списка пакетов:
$ sudo apt updateА также, обновите сами пакеты до актуальных на текущий момент версий:
$ sudo apt upgradeТак как Kafka создан при помощи Java и Scala, а также для запуска Kafka требуется установка jre;
$ sudo apt install default-jreПосле чего, нужно будет удостовериться, что необходимый пакет Java установлен:
$ java -version
Создание служебного пользователя для Kafka
Поскольку Kafka – это приложение, работающее через сеть, необходимо создать для него специальную учётную запись. Это позволит уменьшить риски для вашего сервера на случай компрометации Kafka. В нашем примере мы будем использовать для этого учётную запись с именем kafka. Создайте пользователя при помощи команды:
$ sudo adduser kafkaДалее, нужно добавить созданного пользователя в группу sudo для предоставления ему прав на установку необходимых зависимостей:
$ sudo adduser kafka sudoТеперь залогиньтесь в системе под учётной записью kafka:
$ su -l kafkaУстановка сервиса Kafka
Установочный пакет Kafka мы загрузим в каталог /tmp. Для чего перейдите в эту директорию:
$ cd /tmpИ загрузите архив Kafka при помощи команды curl. На момент написания статьи актуальной версией Kafka являлась версия 3.2.1, поэтому в нашем примере команда для загрузки выглядит следующим образом:
$ curl -LO https://dlcdn.apache.org/kafka/3.2.1/kafka_2.13-3.2.1.tgzЕсли вдруг окажется, что команда curl отсутствует в вашей системе, установите её с использованием следующей инструкции:
$ sudo apt install curlПосле того, как вы загрузили архив, создайте каталог для распаковки дистрибутива. Каталог будет иметь название kafka:
$ mkdir ~/kafkaИ перейдите в созданную директорию:
$ cd ~/kafkaТеперь распакуйте загруженный архив при помощи команды:
$ tar -xvzf /tmp/kafka_2.13-3.2.1.tgz --strip 1В данном случае мы используем опцию --strip 1, которая позволит нам распаковать архив непосредственно в каталог ~/kafka, без использования каких-либо других подкаталогов.
Настройка сервера Kafka
По умолчанию Kafka не позволяет удалять тему передаваемого сообщения, так называемый топик. Сообщения могут публиковаться в данном топике, который представляет собой категорию, группу или название канала. Мы можем отредактировать конфигурацию, чтобы это изменить.
Текущие настройки Kafka содержатся в файле server.properties. Чтобы внести в него изменения, используйте текстовый редактор nano:
$ cd ~/kafka/config/
$ nano server.propertiesДобавьте в файл строку, которая позволит удалять топики:
delete.topic.enable = trueТакже, найдите и внесите изменения в строку log.dirs, чтобы обеспечить хранение журналов событий Kafka в домашнем каталоге:
log.dirs=/home/kafka/logsТеперь, необходимо создать соответствующий файл для сервиса kafka. При помощи него вы сможете запускать, останавливать и перезапускать службу. Создайте файл при помощи редактора nano:
$ sudo nano /etc/systemd/system/kafka.serviceНаполните файл следующим содержимым:
[Unit]
Requires=zookeeper.service
After=zookeeper.service
[Service]
Type=simple
User=kafka
ExecStart=/bin/sh -c '/home/kafka/kafka/bin/kafka-server-start.sh /home/kafka/kafka/config/server.properties > /home/kafka/kafka/kafka.log 2>&1'
ExecStop=/home/kafka/kafka/bin/kafka-server-stop.sh
Restart=on-abnormal
[Install]
WantedBy=multi-user.targetПосле завершения редактирования закройте файл, сохранив внесённые в него изменения.
Также необходимо создать файл для службы zookeeper:
$ sudo nano /etc/systemd/system/zookeeper.serviceСодержимое данного файла будет таким:
[Unit]
Requires=network.target remote-fs.target
After=network.target remote-fs.target
[Service]
Type=simple
User=kafka
ExecStart=/home/kafka/kafka/bin/zookeeper-server-start.sh /home/kafka/kafka/config/zookeeper.properties
ExecStop=/home/kafka/kafka/bin/zookeeper-server-stop.sh
Restart=on-abnormal
[Install]
WantedBy=multi-user.targetПосле того, как вы сохранили изменения и закрыли файл, запустите службу kafka:
$ sudo systemctl start kafkaДля того, чтобы убедиться, чтобы служба запустилась и работает без ошибок, посмотрите её статус:
$ sudo systemctl status kafkaЕсли всё хорошо, то вывод команды должен выглядеть примерно следующим образом:
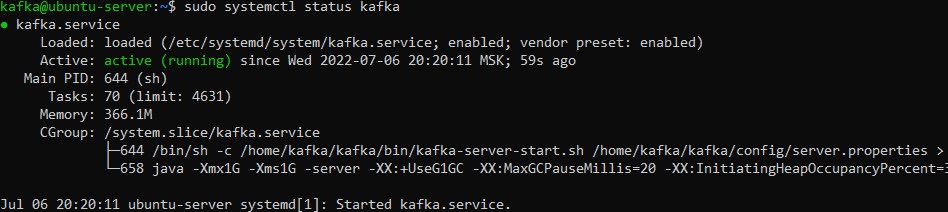
Сервис kafka работает. Но при перезагрузке сервера служба не запустится самостоятельно. Поэтому необходимо включить автозапуск служб kafka и zookeeper при помощи следующих команд:
$ sudo systemctl enable zookeeper
$ sudo systemctl enable kafkaПри этом, есть, как говориться, небольшой нюанс.
А именно, начиная с релиза Kafka 2.4.0 во многих случаях при перезагрузке сервера служба kafka сразу после старта останавливается с ошибкой:

Это происходит из-за того, что после перезапуска служба kafka пытается сопоставить свой локально хранимый ididzookeeper, который при перезапуске изменился.
Для запуска службы kafka без данной ошибки есть два несложных способа.
Способ первый – в файле meta.properties необходимо закомментировать строку, содержащую i кластера Kafka:d
$ cd /home/kafka/logs/
$ nano meta.propertiesПоскольку строка становится комментарием при наличии в её начале символа #, то изменённый файл meta.properties будет выглядеть примерно следующим образом:
#
#Thu Aug 04 14:17:33 MSK 2022
broker.id=0
version=0
#cluster.id=wBfl57cjSSK4EepSkSifuQЗакройте файл с сохранением изменений и перезапустите службу kafka:
$ sudo systemctl restart kafkaСпособ второй – необходимо подменить id кластера Kafka значением id кластера Zookeeper. Для этого из файла /home/kafka/kafka/kafka.log скопируйте корректный cluster.id:
$ cd /home/kafka/kafka/
$ nano kafka.log
И вставьте его в строку cluster.id файла meta.properties:
$ cd /home/kafka/logs/
$ nano meta.properties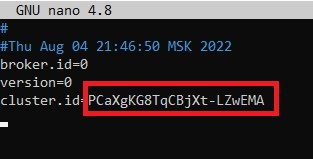
После чего, также, закройте файл meta.properties сохранив изменения и перезапустите службу kafka:
$ sudo systemctl restart kafkaЕстественно, после следующей перезагрузки виртуального сервера данную процедуру по первому или по второму способу придётся повторить. Учитывайте это.
Проверка сервера Kafka
На данном этапе мы протестируем, как Kafka умеет отправлять и получать сообщения. Чтобы убедиться в функциональности сервера, мы опубликуем сообщение с текстом Privet попробуем его получить.
Для данного теста нам понадобится, во-первых, издатель. Это – тот, кто будет публиковать тестовое сообщение. И, во-вторых, нам нужен будет подписчик. Это – тот, кто получит отправленное сообщение.
Итак, под учётной записью kafka создайте новую тему. В качестве теста мы создадим тему, которая будет называться New_Topic:
$ ~/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic New_Topic
Также, из командной строки можно при помощи скрипта kafka-console-producer.sh создать издателя. Для этого в качестве аргументов потребуется указать имя хоста, порт и название темы.
Теперь в теме New_Topic опубликуйте сообщение с текстом Privet:
$ echo "Privet" | ~/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic New_Topic > /dev/nullДалее, с использованием скрипта kafka-console-consumer.sh создайте подписчика. В параметрах необходимо указать имя хоста сервера zookeeper, порт и имя темы. Данная команда сможет получить отправленное сообщение:
$ ~/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic New_Topic --from-beginningОбратите внимание на опцию --from-beginning. Этот параметр обеспечивает получение сообщений, отправленных ещё до создания подписчика.
Если всё работает правильно, под введённой командой вы увидите полученное сообщение с текстом Privet:

Запущенная команда продолжит ожидать сообщения, которые могут опубликованы далее. В качестве теста, откройте ещё один терминал, и в нём снова запустите издателя. При этом в первом терминале, где запущен подписчик, вы сможете получать следующие сообщения, отправленные с терминала издателя.
Прервать работу скрипта, запустившего подписчика, можно при помощи комбинации клавиш Ctrl+C.
Повышение уровня безопасности сервера Kafka
Теперь, когда стадия установки и настройки сервера Kafka завершена, можно лишить администраторских привилегий учётную запись kafka. Для этого завершите все подключения к серверу пользователя kafka. После чего подключитесь с вашему VPS под учётной записью, имеющей полномочия sudo. Следующей командой исключите пользователя kafka из группы sudo:
$ sudo deluser kafka sudoДалее, чтобы стало невозможным прямое подключение к серверу под учётной записью kafka, заблокируйте пароль этого пользователя. Данное действия значительно повысит уровень безопасности сервера Kafka:
$ sudo passwd kafka -lС этого момента залогиниться под учётной записью kafka сможет только пользователь root, либо пользователь имеющий привилегии sudo.
В случае, если вам понадобится разблокировать учётную запись kafka, вы сможете сделать это при помощи команды passwd с использованием опции -u:
$ sudo passwd kafka -uУстановка KafkaT (опционально)
Ещё один инструмент, позволяющий просматривать информацию о кластере Kafka, а также выполняющий определённые административные действия прямо из командной строки, это – KafkaT. Перед его установкой необходимо будет проинсталлировать Ruby, так как KafkaT написан именно на нём. Помимо Ruby в установку нужно будет включить пакет build-essential, поскольку он также применяет для KafkaT некоторые зависимости:
$ sudo apt install ruby ruby-dev build-essentialДалее запустите установку KafkaT используя команду gem:
$ sudo CFLAGS=-Wno-error=format-overflow gem install kafkatЗдесь, мы использовали компиляционный параметр Wno-error=format-overflow для того, чтобы подавлять предупреждения от сервера zookeeper во время инсталляции KafkaT.
Конфигурация KafkaT содержится в файле .kafkatcfg. По умолчанию такого файла не существует, поэтому его нужно создать:
$ nano ~/.kafkatcfgВ этот файл необходимо внести информацию о том, в каком каталоге находится Kafka, журналы событий сервера Kafka, а также информацию о сервере Zookeeper:
{
"kafka_path": "~/kafka",
"log_path": "/home/kafka/logs",
"zk_path": "localhost:2181"
}После сохранения файла .kafkatcfg можно начинать использование KafkaT. Для начала примените следующую команду, которая покажет вам информацию обо всех партициях Kafka:
$ kafkat partitionsВывод команды должен выглядеть примерно следующим образом:
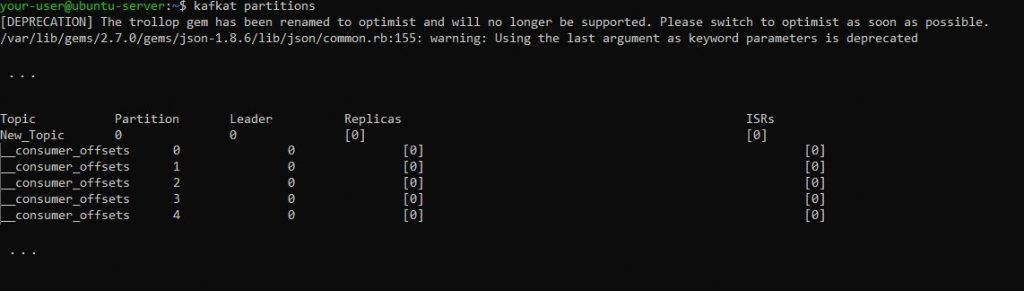
Текст вывода содержит информацию по теме New_Topic, а также данные по внутренней теме Kafka – __consumer_offsets. В ней хранится информация, относящаяся к клиентам сервера Kafka. Если в выводе присутствуют строки, начинающиеся с __consumer_offsets, то их можно игнорировать совершенно спокойно.
Для получения более полной информации по данному продукту обратитесь в репозиторий Kafka на GitHub.
Заключение
Таким образом, мы развернули сервис Apache Kafka на виртуальном сервере, работающем на Ubuntu 20.04. Более полная информация об установке, настройке и использованию Kafka доступна в документации по данному программному продукту.
