
ClickHouse – столбцовая или колоночная система управления базами данных, которая позволяет выполнять онлайн-запросы на структурированных больших данных (Big Data). СУБД ClickHouse разработана компанией Yandex для онлайн обработки аналитических запросов (OLAP). ClickHouse использует диалект SQL, который поддерживает декларативный язык запросов во многих случаях совпадающий с SQL стандартом. В этом руководстве мы изучим, как установить и использовать ClickHouse на вашем сервере с CentOS Stream.
Установка ClickHouse
Инсталляцию ClickHouse на вашем VPS необходимо производить пользователем, имеющим привилегии sudo, но не являющимся учётной записью root.
Для установки сервиса мы будем использовать предкомпилированные бинарники из tgz архивов.
Для начала, перед тем, как мы приступим к загрузке архивов с дистрибутивами, нужно узнать номер последней стабильной версии ClickHouse. Это можно сделать перейдя на страницу репозитория, и выбрать самый свежий из выложенных архивов. На момент написания статьи номер последней версии – 20.2.1.2183, эту версию ClickHouse мы и будет устанавливать.
Создайте в домашнем каталоге вашего пользователя специальную директорию clickhouse, перейдите в неё и при помощи команды curl загрузите архивы последней версии ClickHouse:
$ cd ~
$ mkdir clickhouse
$ cd clickhouse
$ curl -O https://repo.clickhouse.tech/tgz/clickhouse-common-static-20.2.1.2183.tgz
$ curl -O https://repo.clickhouse.tech/tgz/clickhouse-common-static-dbg-20.2.1.2183.tgz
$ curl -O https://repo.clickhouse.tech/tgz/clickhouse-server-20.2.1.2183.tgz
$ curl -O https://repo.clickhouse.tech/tgz/clickhouse-client-20.2.1.2183.tgzВ чистой CentOS Stream по умолчанию не установлен архиватор tar, поэтому, если вы не инсталлировали его ранее, необходимо будет проделать это сейчас. Архиватор понадобится для распаковки скачанных файлов:
$ sudo dnf install tarТеперь, распакуйте полученные архивы:
$ tar -xzvf clickhouse-common-static-20.2.1.2183.tgz
$ tar -xzvf clickhouse-common-static-dbg-20.2.1.2183.tgz
$ tar -xzvf clickhouse-server-20.2.1.2183.tgz
$ tar -xzvf clickhouse-client-20.2.1.2183.tgzИ запустите установку пакета следующими командами:
$ sudo clickhouse-common-static-20.2.1.2183/install/doinst.sh
$ sudo clickhouse-common-static-dbg-20.2.1.2183/install/doinst.sh
$ sudo clickhouse-server-20.2.1.2183/install/doinst.sh
$ sudo /etc/init.d/clickhouse-server startПоследней командой должен запуститься сервер ClickHouse. Если это произошло, вывод команды должен быть следующим:

Чтобы проверить, запущен ли сервис, наберите в командной строке:
$ sudo service clickhouse-server status
Останется запустить инсталляцию клиента:
$ sudo clickhouse-client-20.2.1.2183/install/doinst.shЕсли сервер ClickHouse запустился без ошибок, вы можете начать использовать консоль для подключения к нему при помощи команды clickhouse-client:
$ clickhouse-client
Для выхода из консоли нажмите Ctrl-D.
Таким образом, вы успешно установили сервер и клиент ClickHouse. Далее, перейдём к запуску СУБД.
Создание базы данных
Для того, чтобы создать или удалить базу данных в ClickHouse, вы можете пользоваться SQL-операторами, запуская их непосредственно из командной строки. Для чего вам нужно подключиться к СУБД, запустив консоль при помощи команды:
$ clickhouse-client --multilineЗдесь, опция --multiline позволит использовать командные запросы, состоящие из нескольких строк.

Теперь наш клиент готов ко вводу запросов. Для того, чтобы увидеть, как работает ClickHouse, давайте попробуем создать свою базу данных. Назовём её, например, test_db. Для создания БД в командной строке консоли наберите:
:) CREATE DATABASE test_db;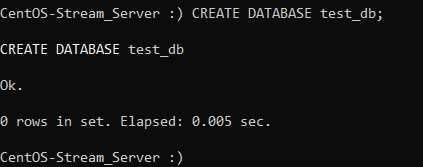
Для использования только что созданной базы данных, нужно переключиться на неё с помощью оператора USE:
:) USE test_db;
В ClickHouse структура таблиц идентична тому, что представляют из себя таблицы в других реляционных СУБД. Для создания таблиц в ClickHouse используется следующий синтаксис:
CREATE TABLE tbl_name
(
col-1_name column_type [options],
col-2_name column_type [options],
...
) ENGINE = engineЗдесь, tbl_name – название таблицы, col-1_name и col-2_name – названия столбцов. Каждый из столбцов должен иметь определённый тип. Среди наиболее часто используемых:
- UInt64 – тип, использующийся для хранения целых чисел в диапазоне от 0 до 18446744073709551615;
- Float64 – тип, использующийся для хранения чисел с плавающей точкой;
- String – тип, использующийся для хранения символьных переменных;
- Date – дата в формате YYYY-MM-DD;
- DateTime – дата и время в формате YYYY-MM-DD HH:MM:SS.
В параметре ENGINE необходимо указать движок, который будет использоваться в таблице. Движки определяют физическую структуру основных данных, возможности табличных запросов, режимы параллельного доступа, поддержку индексов. Различные типы движков подходят для различных требований к приложениям. Наиболее часто используемым и одним из самых распространённых типов является MergeTree.
Создание таблицы
Поскольку мы уже переключились на нашу тестовую базу, мы можем создать в ней новую таблицу. Структура нашей таблицы будет следующей:
id– первичный ключ или, другими словами, уникальный идентификатор строки;val– десятичное число;word– символьная строка;dat– дата и время.
Для создания нашей таблицы в консоли ClickHouse наберите:
:) CREATE TABLE test_tbl (
:] id UInt64,
:] val Float64,
:] word String,
:] dat DateTime
:] ) ENGINE = MergeTree()
:] PRIMARY KEY id
:] ORDER BY id;После того, как вы идентифицировали в таблице столбцы, вам нужно указать для вашей таблицы движок. Мы укажем MergeTree. Семейство движков MergeTree рекомендуется использовать для производственных баз данных благодаря их оптимизированной поддержке больших вводов в реальном времени, общей надёжности и поддержке запросов.
Также, после указания типа движка, в введённой команде мы использовали опцию PRIMARY KEY, которая определяет столбец id как первичный ключ, и опцию ORDER BY, которая указывает, что данные в таблице будут отсортированы по колонке id.
Результатом выполнения этой команды будет создание таблицы test_tbl:
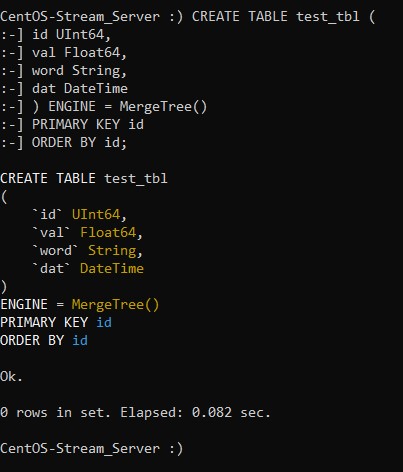
Таким образом, мы создали тестовую базу данных и таблицу в ней. Далее, мы посмотрим, как можно вставить данные в таблицу, обновить и удалить их.
Вставка, обновление и удаление данных
В этом разделе мы попробуем вставлять, обновлять и удалять строки и столбцы в нашей таблице test_tbl.
Синтаксис команды для вставки строки в таблицу имеет следующий вид:
INSERT INTO tbl_name VALUES (col-1_value, col-2_value, ....);Теперь, наберите в командной строке консоли следующий инструкции для добавления строк в нашу таблицу:
:) INSERT INTO test_tbl VALUES (1, 11.1, 'string 1', '2021-01-01 01:01:01');
:) INSERT INTO test_tbl VALUES (2, 22.2, 'string 2', '2021-02-02 02:02:02');
:) INSERT INTO test_tbl VALUES (3, 33.3, 'string 3', '2021-03-03 03:03:03');
:) INSERT INTO test_tbl VALUES (4, 44.4, 'string 4', '2021-04-04 04:04:04');
:) INSERT INTO test_tbl VALUES (5, 55.5, 'string 5', '2021-05-05 05:04:05');При успешном добавлении строк в таблицу вывод каждой из этих команд выглядит как:

Синтаксис команды, предназначенной для добавления в таблицу колонок выглядит следующим образом:
ALTER TABLE tbl_name ADD COLUMN col_name col_type;Используя это правило, добавьте в таблицу столбец, который будет содержать текстовые данные (комментарий):
:) ALTER TABLE test_tbl ADD COLUMN description String;В случае удачного добавления колонки вывод команды будет следующим:
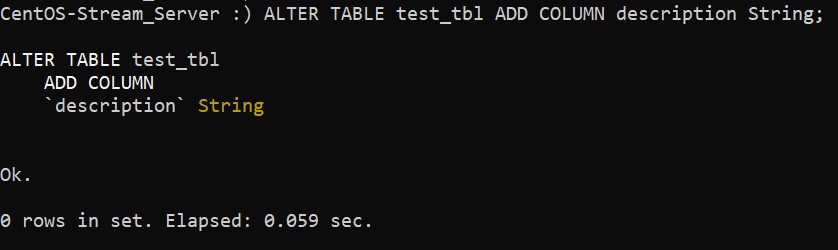
Последние версии ClickHouse не поддерживают обновление и удаление отдельных строк. При этом ClickHouse поддерживает пакетное обновление и удаление, используя для этих целей особый синтаксис.
Команда для обновления пакета строк в ClickHouse выглядит следующим образом:
ALTER TABLE tbl_name UPDATE col-1 = val-1, col-2 = val-2 ... WHERE filter-conditions;Теперь запустите изменение содержимого столбца word в строках, где значение val больше, чем 30:
:) ALTER TABLE test_tbl UPDATE word = 'Updated String' WHERE val > 30;При успешном применении изменений на экране будет следующее:
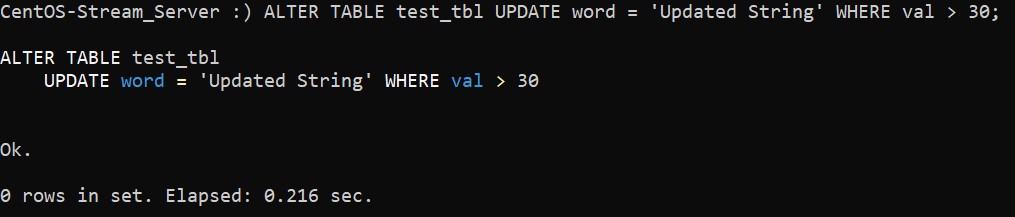
В свою очередь, команда, удаляющая строки из таблицы, имеет следующую структуру:
ALTER TABLE tbl_name DELETE WHERE filter_conditions;В качестве теста давайте удалим из таблицы записи, значение val у которых меньше, чем 20:
:) ALTER TABLE test_tbl DELETE WHERE val < 20;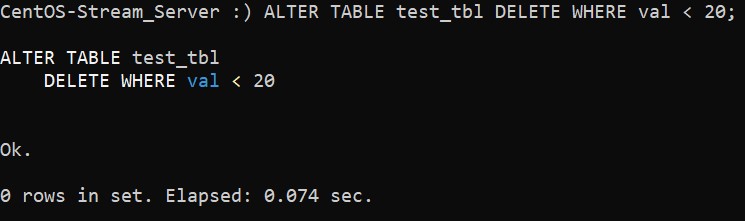
Также, в ClickHouse можно удалить колонку из таблицы. Такая команда имеет следующий формат:
ALTER TABLE tbl_name DROP COLUMN col_name;Таким образом, мы может удалить из нашей таблицы столбец description, который мы добавили ранее:
:) ALTER TABLE test_tbl DROP COLUMN description;Вывод после выполнения удаления колонки выглядит следующим образом:
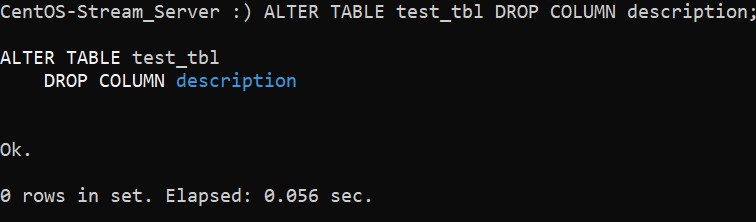
И теперь, после того, как мы изучили возможность добавления, изменения и удаления данных в таблицах ClickHouse, можно перейти к запросам данных.
Запрос данных
В ClickHouse запросы создаются на языке, в основе которого лежит SQL. В этом разделе мы сделаем некоторые выборки данных из нашей тестовой таблицы с помощью запросов к ней.
Запросы позволяют получать данные, отфильтрованные по определённым условиям. В SQL основным оператором, на основе которого формируются запросы, является оператор SELECT. Этот оператор имеет следующий синтаксис:
SELECT function-1(col-1), function-2(col-2) FROM tbl_name WHERE filter_conditions row_options;В качестве теста запустите команду запроса, который покажет нам данные из столбцов val и word, для строк, где колонка word содержит Updated String:
:) SELECT val, word FROM test_tbl WHERE word = 'Updated String';Вывод после выполнения этого запроса будет выглядеть так:
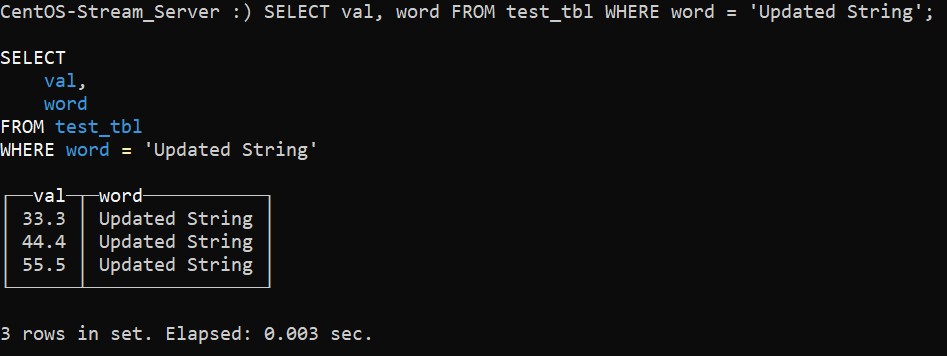
Кроме всего прочего, в ClickHouse широко применяются так называемые агрегационные запросы. Такие запросы оперируют с набором значений и возвращают единичное выходное значение. К таким запросам, поддерживаемым ClickHouse относятся, например, COUNT. Этот оператор возвращает количество строк, которое соответствует указанным условиям. Другой оператор подобного типа – SUM. Он возвращает сумму значений указанных колонок. Подобным образом запрос AVG возвращает среднее значение указанных колонок.
Теперь, чтобы увидеть, как это работает, мы запросим у нашей тестовой таблицы количество записей, содержащейся в ней:
:) SELECT COUNT() FROM test_tbl;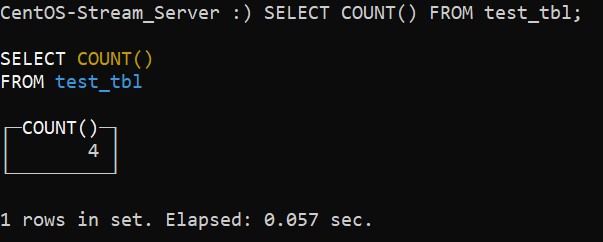
Теперь, запросите сумму всех записей по столбцу val:
:) SELECT SUM(val) FROM test_tbl;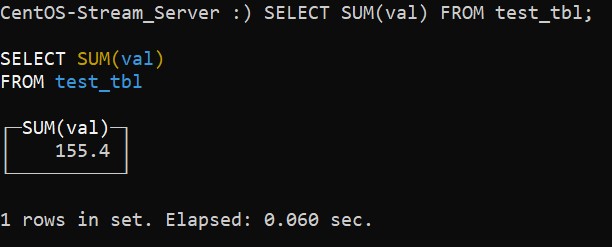
Удаление таблиц и баз данных
На этом этапе первоначальго знакомства с ClickHouse мы удалим нашу тестовую таблицу, а потом и базу данных.
Оператор удаления таблицы имеет следующий синтаксис:
DROP TABLE tbl_name;Следующая команда удалит таблицу test_tbl:
:) DROP TABLE test_tbl;
Команда удаления базы данных очень похожа на предыдущую:
:) DROP DATABASE test_db;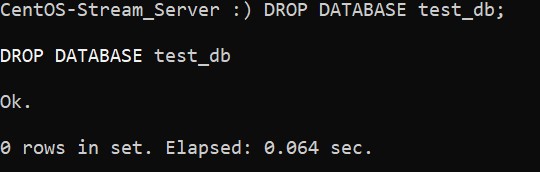
Таблица, а потом и база данных удалены. Теперь нам нужно будет настроить удалённый доступ к нашей СУБД.
Настройка брандмауэра (опционально)
В этом разделе мы настроим удалённый доступ к серверу ClickHouse для того, чтобы работать с ClickHouse не только локально.
Настройка удалённого доступа заключается во внесении изменений в конфигурацию межсетевого экрана. Во-первых, необходимо отредактировать файл config.xml:
$ cd /etc/clickhouse-server
$ sudo vi config.xmlЗдесь вам нужно будет раскомментировать строку:
<!– <listen_host>0.0.0.0</listen_host> –>После чего закройте файл с сохранением изменений и перезапустите службу clickhouse-server:
$ sudo service clickhouse-server restart
Далее, добавьте IP-адрес удалённого сервера в зону, которая называется public, например:
$ sudo firewall-cmd --permanent --zone=public --add-source=192.168.1.123/24Теперь, откройте в брандмауэре доступ для портов 8123 и 9000:
$ sudo firewall-cmd --permanent --zone=public --add-port=8123/tcp
$ sudo firewall-cmd --permanent --zone=public --add-port=9000/tcpИ перезапустите брандмауэр:
$ sudo firewall-cmd --reloadВывод об успешном выполнении этих команд должен выглядеть так:
После того, как вы произвели данные настройки, ваш сервер ClickHouse стал доступен с IP-адреса, добавленного в брандмауэр. Чтобы осуществить соединение с сервером ClickHouse со стороны удалённой машины, необходимо на втором сервере произвести настройки, описанные в разделе “Установка ClickHouse”. При этом, обязательно убедитесь, что на нём установлен clickhouse-client.
Далее, подключитесь ко второму серверу и запустите консоль ClickHouse:
$ clickhouse-client --host XXX.XXX.XXX.XXX --multilineЗдесь XXX.XXX.XXX.XXX – IP-адрес вашего сервера ClickHouse.
В случае успешного подключения вы должны увидеть следующий вывод:

Заключение
Таким образом, вы установили СУБД ClickHouse на свой VPS, создали базу данных и таблицу, попробовали добавлять данные в неё, а также, изменять и удалять их. Это было первоначальное знакомство с тем, как установить и использовать ClickHouse на сервере с CentOS Stream.
